
Attack of the clones - removing copied websites from the internet
It's an increasingly-common experience for online publishers to discover that their content has been stolen wholesale, and posted on a different domain. This isn't usually just one or two articles being copied by a competitor, but the whole site (or whole sections of it) being reproduced on a new domain. In many cases, this copied content out-ranks the original on Google when initially discovered. What can you do if this happens to your site?
What does this look like?
There you are, running your own site, regularly publishing quality news articles and long reads on LegitimatePublication.com. Unbeknownst to you, some nefarious ne'er-do-well has registered AwesomeRolexAndDietPillDiscounts.com, and has begun to fill it with content from your site. At some point, you find out about this clone. That can happen in any number of ways, with the most common being:
- Google search: While checking Google to see how your latest article is performing, you notice that the headline and article are there, but they're clicking through to a domain you don't recognise as being one of yours. Uh oh!
- Google analytics: Within analytics, you notice that the hostnames your site runs on suddenly has a strange new entry, AwesomeRolexAndDietPillDiscounts.com. It looks like somebody has copied your site content, including your analytics tags, and is now running it on that domain. Bad times indeed!
- User report: If you've an active user base on social media, one of them may have come across your content on a domain they didn't recognise, and reported it to you.
After a quick check with marketing to confirm that this isn't a particularly wild white label plan they cooked up, you confirm that this domain has nothing to do with your site, and the people behind it are taking your content without permission! Rubbing salt in the wound, this clone site looks identical to yours - they've even copied your logo!
In some cases, the content has been scraped, so is a "moment in time" snapshot of your site. But more commonly, the clone site is pulling in "live" content. This means that when a new article is published on LegitimatePublication.com, within minutes it is also listed on AwesomeRolexAndDietPillDiscounts.com. The layout of both sites appear to be almost identical. Typically things like contact email addresses in the footer will have been removed, or swapped out for a mailbox under the clone site's control, but the sites look otherwise identical.
How are they doing it?
Typically the above behaviour is caused by someone setting up a proxy. Trying to access any link on AwesomeRolexAndDietPillDiscounts.com will cause the clone site server to access the same page on LegitimatePublication.com. The content will typically pass through a small modification script on the clone site server (to perhaps alter the footer email address as mentioned above, or possibly modify the site name or logo), and then serve the content. This is a much simpler way to set up this kind of clone site, versus relying on regular scraping and storage of that data.
There's a slightly modified version of this where somebody has set up a website which imports content from lots of different sites. They usually look like a standard Wordpress template, and may have the Science section copied from a science website, Sports from a sport site, and so on. While this is occasionally done via custom scrapers of the multiple sites involved, it is more commonly done by using an RSS-to-post plugin in Wordpress, regularly importing the RSS feed of the original sites. For this reason, this variant tends to impact sites which publish per-category RSS feeds, but is significantly less common than the proxy version.
Why are they doing it?
There are a couple of reasons why someone would want to set up this kind of clone site. The first is ad revenue - if you can get a domain approved by Google ads, put good content on it, and build up some inbound traffic, it can generate decent money from display ads. That is, until Google become aware of the copyright theft involved, and shut it down.
The more common reason is to build up a domain history for later re-use or sale of the whole site. Having a domain which Google discovers, and then sees regularly publishing quality content over a prolonged period, can lead to Google crediting the domain with a degree of authority and value in terms of Google ranking. At some point down the line, the site content can then be changed to be full of links to other sites who pay the clone site operator to pass on link value to them. Why? There can be a short-term gain in ranking for those sites, which will in turn boost their own revenue. The folks running the clone typically don't get into the link-selling business themselves, but will build up a domain like this to have "good authority", and then sell it on to brokers in that area for later re-sale.
But if it's a new domain, with no inbound links, surely Google doesn't rank that above a long-established, well-known publisher?
Oh, you sweet summer child... Unfortunately this happens far more often than you'd expect! Google balances a number of different signals to determine what appears prominently in its rankings. While domain authority and age are strong signals, "freshness" of content is often given a strong signal boost, particularly when it comes to news.

For this reason, publishers will often first see these clones when their own sites are being outranked in Google, for their own content. This creates a sense of urgency to get this resolved - the longer these sites hang around, the more the concern is that Google ends up inaccurately classifying the original site as having duplicated the content of the clone site, and enshrine the clone site in the rankings as the "originator" of the content it has stolen.
How do we stop it?
Our goal is to get the duplicated content removed from the internet, and also Google's index. As this is the internet, most of the terminology for removal comes from US law. But as most of the offenders don't live in the US (and so are not subject to US law), this process can often be a frustrating and drawn-out one, with some of the steps being repeated several times until finally it is resolved.
The term DMCA becomes relevant at this point. The Digital Millennium Copyright Act is US legislation to protect the rights of copyright holders. Many US-based hosting companies will have specific DMCA / copyright abuse contact addresses, as there are severe penalties under US law for not responding promptly to notifications of copyright theft. Now, again, most of the people you'll be contacting are not under US jurisdiction, but let's make use of DMCA templates for convenience when dealing with service providers.
1. Contact the site owner and ask for removal
This seems counter-intuitive if we believe we're the victim of a deliberate content thief, but many of the latter steps require us to first make a "good faith" effort to contact the site owner before escalating the removal requests. Finding the contact information of the site owner is often a challenge. In some cases, they don't modify the contact information of the original site (leaving your contact info in place!), so there's no designated way to contact them. Additionally, with the onset of GDPR, privacy rules mean that running a whois on the domain will typically return no useful contact information for the site owner.
More commonly, they'll have a contact form on the site, or a modified email address listed as a contact address. In either case, a message should be sent, explaining:
- You're contacting them on behalf of LegitimatePublication.com
- There has been wholesale copying of content on their site, AwesomeRolexAndDietPillDiscounts.com. This copying is not authorised by the copyright holder.
- List several examples of the copied content, and the corresponding original urls on your own site.
- Ask for immediate removal of all copied content, for them to cease and desist from continuing to copy content, and to confirm same by return mail.
This mail will be ignored in 99% of cases, so we move on to the hosting provider.
2. Escalate to the hosting provider
First we have to find the host. This is typically done by:
- Pinging the domain, to get an IP address.

- Run a
whoison the IP. There will be a huge amount of information shown here - we care about who the host company is, and what "Abuse" contact they make available.
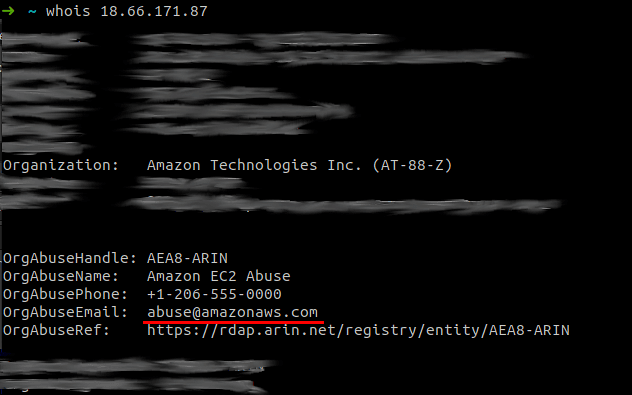
Once we have the abuse@ address, we'll put together a more strongly-worded email. The majority of hosts have some operation in the US, or are at least more sensitive to US-based legal threats than the folks setting up the fake sites, so we can use a DMCA-based template:
My name is INSERT NAME and I am the INSERT TITLE of INSERT COMPANY NAME, working on behalf of CLIENT NAME. A website that your company hosts (according to WHOIS information) is infringing on at least one copyright owned by CLIENT NAME.
A wholesale copy of our site at CLIENT URL has been made available on the domain CLONE DOMAIN, served from your servers without permission of CLIENT. A sample of the copied articles, to which we own the exclusive copyrights, can be found at:
PROVIDE WEBSITE URL FOR SEVERAL ORIGINAL ARTICLESThe unauthorized and infringing copies can be found at:
PROVIDE WEBSITE URL FOR CORRESPONDING COPIESThis letter is official notification under Section 512(c) of the Digital Millennium Copyright Act (”DMCA”), and I seek the removal of the aforementioned infringing material from your servers. I request that you immediately notify the infringer of this notice and inform them of their duty to remove the infringing material immediately, and notify them to cease any further posting of infringing material to your server in the future.
Please also be advised that law requires you, as a service provider, to remove or disable access to the infringing materials upon receiving this notice. Under US law a service provider, such as yourself, enjoys immunity from a copyright lawsuit provided that you act with deliberate speed to investigate and rectify ongoing copyright infringement. If service providers do not investigate and remove or disable the infringing material this immunity is lost. Therefore, in order for you to remain immune from a copyright infringement action you will need to investigate and ultimately remove or otherwise disable the infringing material from your servers with all due speed should the direct infringer, your client, not comply immediately.
I am providing this notice in good faith and with the reasonable belief that rights my company owns are being infringed. Under penalty of perjury I certify that the information contained in the notification is both true and accurate, and I have the authority to act on behalf of the owner of the copyright(s) involved.
Should you wish to discuss this with me please contact me directly.
Thank you.
Send this email to the provider, and then wait. In the majority of cases, you may receive an automated "your ticket has been received and will be dealt with" message. But, beyond that, it's very rare for an acknowledgement to be sent by the host, even when the content has been removed. This means that you'll be left to periodically check the domain to see if it has been cleaned or, more likely, removed entirely.
If you have not seen the site removed after 3-4 business days, check on the host's website for their contact details. They should be responding to the abuse@ information on the whois record, but their website may also have a specific contact form for takedown / DMCA notices. If not, send the email to the abuse@ address again, and CC in any contact information you can find for the hosting provider from their website or social media channels.
3. Google
Run a site:CLONE DOMAIN search in Google. If there are non-zero results (and there usually are, if this clone site was originally noticed via Google results!), then start to file copyright complaints. Google provide a wizard which will walk you through this process. The list of copied article URLs from our DMCA complaint letter will be helpful to have to hand here, as Google also ask for examples of the copyright infringement.
How do I know if it worked?
Unfortunately it is very rare to get any kind of feedback from the folks involved in the process above. Generally, hosting providers will remove the content within a working day. Checking the clone domain repeatedly is unfortunately the only way to know if they've been removed or not.
Google also tend to take 1-2 business days to remove the offending results. Again, repeatedly checking the Google results for the same site:CLONE DOMAIN query is how you'll usually find out if they've taken action.
Is there anything else we can do to kill off these clones?
If the client site is being actively proxied (rather than scraped), it may be possible to put some technical countermeasures in place.
First, start tailing the logs on your site. There will be a lot of requests coming in, so filter this tail to look only for a really specific parameter, which doesn't occur naturally on the site. Let's say something like ?myweirdparam=1.
Next, go to the clone site, and request a url with that parameter on it.
If the clone site is proxying content, then we can expect to see a request from the clone site's server, revealing their IP. You can then take this IP, and block it at the edge of your site's network (via firewall rule, or load balancer IP ban).
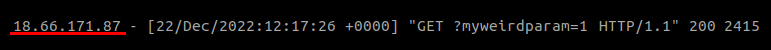
Danger here! Before implementing any ban, check the IP address closely. If there is something like a misconfigured reverse proxy, or the web server not passing client IPs through correctly from a layer like Cloudflare on the edge of the network, this IP may not belong to the clone site's server, but one of the machines responsible for serving your content to the outside world! Blocking that IP would mean taking the site down for all visitors. Sure, it would solve our clone site issue, but does feel a little bit on the "cure is worse than the disease" side of things! So check the IP via whois, and it should line up with the hosting provider we identified earlier.
Are there any other ways we could mess with these content thieves?
Once the IP has been identified, it is possible to serve content specifically to that user. Perhaps your code now checks for that IP, and when it is found, all articles get replaced by the lyrics to Never Gonna Give You Up, with all photos changed to a profile of Rick Astley. Alternatively, the javascript can be replaced by code which will kill the site, or force a redirect back to your site.

These are a very satisfying type of change to make! When this garbage content starts to fill up the clone site, it can be both funny to see and feel quite rewarding. We've short-circuited a drawn-out legal process, involving non-responsive hosts - what's not to love? But this approach, fun as it may be, is a very high-risk thing to do. With things like site caching at different layers of the web application stack, this garbage content may end up being cached on your side, and then served to legitimate users trying to visit your site. So while this "mess with them" approach is very tempting, there are big risks with it! The safer option is the proxy blocking approach detailed above.
